








Если всё, что говорят о знаменитой концепции utility computing, верно, то в будущем каждый потребитель информационных технологий сможет, условно говоря, открыть кран и «налить» себе информацию необходимого количества и качества. В таком случае информационные хранилища по своей простоте должны быть сравнимы с наливным резервуаром. При стремлении же к простоте количество значимых для пользователя элементов внутренней структуры хранилищ должно сводиться к минимуму вплоть до «стирания» вроде бы естественных границ между программными и аппаратными решениями, между понятиями структурированный и неструктурированный контент. Наверное, вплотную к этому мы еще не подошли, но о некоторых моментах взаимопроникновения технологий говорить уже вполне можно.
Резервирование, доводимое до совершенства
Если говорить о современных системах хранения данных, то они год от года все больше «обрастают» решениями, которые по сути можно рассматривать как неотъемлемую часть самих аппаратных комплексов и которые часто реализуются комбинированным программно-аппаратным способом на низком уровне. Известна теснейшая связь между СХД и программными комплексами резервного копирования данных, которые, как отмечают эксперты, за последние год-два пополнились некоторыми новыми категориями функциональных разработок, позволяющих получить более эффективные и менее дорогостоящие решения. Речь идет о таких очень часто обсуждаемых в западных публикациях направлениях, как технология мгновенных снимков данных (snapshot), непрерывная защита данных (continuous data protection — CDP) и дедупликация данных (data deduplication).
По утверждениям западных аналитиков, существует по крайней мере несколько причин активного развития подобных технологий, основными из которых являются банальный количественный рост информационных ресурсов, а также тот факт, что в эпоху существенного повышения роли онлайновых ресурсов в бизнесе большинству компаний все труднее бывает выделить какое-то время на резервирование информации. Иными словами, даже в формально нерабочие часы остановка систем или хотя бы известное ограничение их функционирования, связанное с процессами резервирования информации, становится практически недопустимым.
Технология дедупликации, которую часто еще называют технологией интеллектуальной компрессии (intelligent compression) или хранилищем одного экземпляра (single-instance storage), предназначена для решения первой задачи и реализует методику сокращения потребностей в физических хранилищах за счет исключения избыточных данных. Избыточность эта составляет далеко не единицы и даже не десятки процентов. Специалистами, в частности, подсчитано, что даже при среднем для бизнеса темпе резервирования данных и использовании общепринятых методик ведения этого процесса 1 Тбайт «полезных» корпоративных данных за свой жизненный цикл порождает порядка 53 Тбайт информации, хранящейся на резервных носителях. Если принять во внимание, что сжатие данных за счет «интеллектуальной компрессии» может быть 20 — 30-кратным (хотя иногда производители заявляют и гораздо большие значения), надо понимать, что методы дедупликации позволяют если не полностью, то в очень значительной мере справиться с указанной избыточностью. И это не говоря о том, что на процессы, связанные непосредственно с копированием, тратится драгоценнейший временной ресурс.
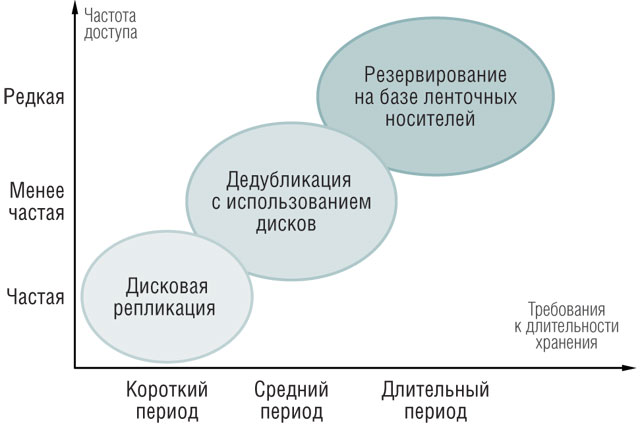
В ряду общепринятых методов резервирования методы, связанные с дедупликацией, начинают занимать некое промежуточное положение между традиционным «дисковым» резервированием и не менее традиционными методиками сохранения данных на магнитной ленте (см. рисунок). Иными словами, технология data deduplication в известном смысле заполняет зазор между представленными на рисунке двумя классическими технологиями, сохраняя производительность, сравнимую с быстродействием перенесения резервных данных на дисковые носители, но обеспечивая в то же время гораздо большую эффективность хранения при средних сроках жизненного цикла тех или иных данных.
Как и положено новой технологии, в лидирующих поставщиках здесь часто числятся недавние фирмы-стартапы, которые тем не менее уже смогли крепко стать на ноги в качестве поставщиков коммерческих систем для корпоративного сектора. Но среди апологетов data deduplication в последнее время появились и очень известные, в том числе и в России, компании. Это, например, EMC, Symantec или NetApp. Недавно EMC приобрела фирму Avamar Technologies, специализирующуюся на дедупликации, что, по утверждению аналитиков, стало первым фактом поглощения крупным вендором производителя в этой пока специализированной нише работы с данными.
Если дедупликация в основном призвана решить проблему количественного роста данных, то вторая отмеченная нами задача, связанная с возрастанием в корпоративном мире значения информационного ресурса реального времени, доступного в режиме 24×7, направлена на иные новые концепции резервирования данных. В таком контексте полезно сказать по крайней мере о трех основных параметрах, манипулирование которыми позволяет добиваться оптимальных характеристик резервного копирования информации. Временное окно, непосредственно выделяемое под процесс резервирования (backup window), — один из этих измеримых индикаторов. Параметр RPO (recovery point objective), в свою очередь, характеризует степень «свежести» данных при восстановлении, или, иными словами, напрямую связан с частотой копирования информации. И наконец, параметр RTO (recovery time objective) определяет тот интервал, в течение которого осуществляется восстановление данных. Во многих компаниях все три ключевых показателя могут измеряться часами, и такая ситуация все меньше их устраивает. Если даже удается выделить время в ночные часы, а связанные с этим процессом ограничения в работе прикладных систем компаниям в принципе подходят (хотя в последнее время всё реже и реже), то потеря данных, скажем, за последние десять часов может оказаться просто критичной. И здесь уже приходится говорить о непрерывной защите данных — технологии, которая в силу еще не устоявшейся на отечественном рынке терминологии пока обозначается оригинальной английской аббревиатурой CDP. Иногда эту технологию также называют непрерывным резервированием (continuous backup), имея в виду, что она позволяет в режиме онлайн отслеживать все текущие изменения в корпоративных данных вплоть до элементарной транзакции и может быть настроена таким образом, чтобы делать фактически мгновенные «снимки реального времени» (snapshot) данных, сбрасывая все имеющиеся изменения в резервное дисковое или же ленточное хранилище. Тем самым появляется возможность существенно повысить эффективность резервирования и частоту, с которой оно производится, а за счет технологических приемов обеспечения работы исключительно с модифицированными данными — возможность снизить параметры RTO, RPO и окно резервирования до значений, близких к нулевым или по крайней мере не превышающих нескольких минут, а иногда и секунд. Что касается вендоров, реализующих CDP в комбинации с технологией snapshots, то если не брать те же стартап-компании, как правило, очень фокусно концентрирующие собственные усилия, а рассматривать наиболее известных игроков на рынке систем хранения, то следовало бы скорее всего повторить названия тех, о которых шла речь в контексте технологий дедупликации.
Идеи, заложенные в наиболее обсуждаемые в настоящее время технологии повышения эффективности резервирования (дедупликацию, непрерывную защиту и мгновенные снимки данных), так или иначе были известны и реализовывались раньше. Однако, как отмечает большинство экспертов, именно в последнее время данные концепции фактически становятся не самостоятельными предложениями, а неотъемлемой частью самих систем резервного хранения. А следовательно, соответствующие решения реализуются не только на программном, но и на аппаратном, а также на комбинированном уровнях.
Наряду с этим можно, пожалуй, отметить еще пару направлений, которые развиваются последнее время в тесном контексте совершенствования устройств хранения данных как таковых. Одно из них — это объектно-ориентированные хранилища (object-based store — OBS), функционирование которых направлено если не на снижение стоимости единицы помещаемой в хранилище информации, то по крайней мере на более интеллектуальное и эффективное манипулирование ею. В основном эта технология, ориентированная на файловые хранилища, и реализуется программным способом. Вместо того чтобы хранить файлы по традиционной схеме, система создает из них объекты, позволяющие более эффективно и в более понятной для специалистов предметной области нотации осуществлять последующий доступ к ним. При этом:
- формируется уникальный идентификатор файла;
- одни и те же файлы (различающиеся, к примеру, лишь датой создания) хранятся в едином объекте;
- создаётся набор метаданных, ассоциируемых с каждым файлом и объектом.
Специалисты утверждают, что подобный механизм выгоден в тех случаях, когда совокупность порождаемых в результате той или иной профессиональной деятельности файлов бывает очень разнообразна по формату, а связи между файлами имеют более сложную, чем обычно, структуру. Классическим примером такой деятельности может служить медицина, опутанная к тому же (в основном, конечно, это касается американского рынка) огромным количеством жестких регулирующих актов. Наиболее заметными поставщиками и соответственно продуктами в этом сегменте рынка являются EMC (Centera), HP (RISS), Archivas Inc. (Archivas Cluster), Storage Technology Corp. (IntelliStore), а также компания Avamar (Axion), которая около года назад стала частью EMC.
И наконец, упомянем еще одну тесно связанную с аппаратными хранилищами концепцию хранения, адресуемого по контенту (content addressed storage — CAS). Согласно ей данные архивируются в системе таким образом, что их физическое положение в хранилище однозначно связано с содержательной информацией и не может быть ни стерто, ни изменено до тех пор, пока не истечет заданный срок. Термин CAS впервые был употреблен компанией EMC в 2002 году в связи с выпуском на рынок продукта Centera, и с того времени эта технология превратилась в направление, которым занимается целый ряд вендоров, в том числе самых известных на рынке (IBM, Sun, HP, Network Appliance, Caringo, ProStore Systems и другие). Принято считать, что системы хранения, адресуемые по контенту, просты и дешевы и хорошо подходят для больших объемов данных, длительность хранения которых велика, а доступ к ним производится нечасто. В бизнес-терминах их связывают все с теми же пресловутыми регулирующими актами (SOX, HIPPA). Интересно отметить тот факт, что применение этих обязательных для исполнения актов очень часто касается использования всех названных выше новых направлений в технологиях хранения. А ведь речь пока шла о технологиях низкого уровня, нередко даже реализуемых аппаратно, в то время как тема регулирующих актов, казалось бы, затрагивает вопросы ведения бизнеса на самом высоком уровне управления.
Всё в одном наборе
Сопряжение программных и аппаратных технологий отмечается не только на низком уровне, и свидетельством тому стало недавнее формирование рынка программно-аппаратных комплексов хранения и обработки данных (data warehouse appliance — DWA). Такие комплексы представляют собой набор тесно интегрированных программных и аппаратных компонентов (прежде всего серверов, систем хранения, операционных систем и баз данных), преконфигурированных и оптимизированных для задач (как правило, аналитических), которые обычно выполняются в среде программных систем хранения. «Изюминкой» этого набора часто становятся дополнительные аппаратные разработки, предназначенные для самого узкого места — участка считывания данных с носителя в оперативную память для обработки конкретного запроса.
Общая же идея состоит в том, что с некоторыми проблемами внедрения и эксплуатации классических хранилищ и витрин данных пользователям не удается справиться быстро, в то время как темп ввода их в эксплуатацию диктуется экспоненциальным количественным ростом данных и возрастающей потребностью в их аналитической обработке по более сложным алгоритмам, чем те, которые в большинстве случаев использовались ранее. Формально комплексы DWA в контексте общепринятой в компьютерной индустрии общей классификации относятся к разделу Business Intelligence. И это говорит о том, что в данном случае агрегация программных и аппаратных компонентов придвигает интегрированное решение весьма близко к бизнесм-задачам. Однако здесь по-прежнему «чистые» технологии хранения информации (как программные, так и аппаратные) играют не последнюю, если не сказать главную, роль.
Есть две компании, специализирующиеся только на DWA, с которыми во многом и ассоциируется направление data warehouse appliance, — это Netezza и Datallegro (последнюю совсем недавно приобрела Microsoft). Широкие возможности по построению комбинаций различных лучших в своем классе решений в случае с DWA создают благодатную почву для партнерства. Так, по направлению систем хранения данных обе эти фирмы тесно сотрудничают с EMC, а по серверному направлению Datallegro, например, имеет тесные партнерские связи с Dell. В отношении баз данных используется практически полный спектр самых популярных на рынке систем, включая известные СУБД с открытым кодом (Postgres и Inrges). Следует также подчеркнуть, что и гранды компьютерной индустрии самых разных сегментов, такие как IBM, HP, Sun, Oracle, также уже вышли на рынок DWA.
Контент — понятие универсальное
Рассмотренную выше концепцию data warehouse appliance можно классифицировать как технологию сопряжения программных и аппаратных компонентов, реализованную на среднем уровне. Здесь уже вполне рельефно очерчены контуры прикладных решений (в данном случае класса BI), но все же значимую роль играют базовые инфраструктурные технологии. Следующей и по сути завершающей ступенью такого сопряжения становятся интеграция инфраструктурных и прикладных систем управления данными. В прикладной области понятие «данные» сейчас трактуется максимально обобщенно, поскольку помимо традиционных для корпоративного мира численных и документарных данных на сегодняшний день все большую роль приобретают медиаданные и разнообразный полуструктурированный контент (например, электронная почта). В результате охвата этих данных едиными прикладными системами контент-менеджмента и подключения к концепции управления данными устройств СХД (со всем арсеналом новейших низкоуровневых принципов манипулирования, о которых мы говорили выше) появляются комплексные предложения. Пока здесь в основном можно назвать предложения от EMC и IBM, хотя, по словам аналитиков, к ним активно подбираются и другие крупные вендоры. Важность связки СХД и контент-менеджмента, как и значимость «сквозных» решений в этой области, в настоящее время сильно возрастает. Поэтому здесь скажем лишь насколько слов о том прикладном функционале, который пока стоит несколько в стороне от продуктов класса «контент-менеджмент» и не слишком широко известен в России, однако имеет прямое отношение к теме нашего разговора.
Системы управления записями (Record Management) иногда классифицируются как часть решений контент-менеджмента, но нередко включаются в линейки продуктов крупных поставщиков корпоративных систем (например, компанией SAP) фактически в виде отдельного решения. Запись в свою очередь трактуется как информационный элемент, который создаётся и поддерживается для формального основания совершения той или иной бизнес-транзакции или доказательства юридической законности определенной сделки. Возрастающая популярность подобных систем в бизнесе идет в ногу с ростом популярности концепции непрерывной защиты данных (CDP), о которой мы говорили выше. И хотя уровень решения проблем управления информацией в обоих случаях совершенно разный, интерес к ним вполне объясним.
Системы корпоративного поиска (Enterprise Search) предлагаются отдельной категорией поставщиков — Autonomy, Coveo, Endeca, FAST (ныне подразделение Microsoft) и отчасти покрывается универсальными поставщиками корпоративного ПО (Oracle, Microsoft). В России подобные системы пока применяются мало. У каждой из них есть свои сильные стороны, но если подходить к их использованию совсем упрощенно, то это своего рода корпоративные поисковые системы, отличающиеся от привычных Google или Yandex тем, что они способны привязать результаты поиска к ролям сотрудников, бизнес-процессам, проектам и пр. Их применение позволяет шире вовлечь неструктурированный контент в оперативную деятельность компании, а также упорядочить работу с ним.
Системы управления мастер-данными (Master Data Management — MDM) содержатся в виде отдельного модуля фактически в любой крупной ERP-, SCM- или иной комплексной транзакционной системе, но иногда предлагаются цемым рядом специализированных поставщиков (например, компанией Kalida). В России несмотря на острую проблему с мастер-данными они используются не часто. С системами управления контентом их роднит то, что в отличие от большинства моделей транзакционных систем, с которыми они тесно связаны, MDM-решения не порождают, а скорее упорядочивают имеющиеся с компании данные. На сей раз речь в большей степени идет о структурированных данных.
